
1. 데이터와 통계
1-1. 데이터를 보는 법
- 사례: 인기 주요관광지점 Top5
: 언제 많이 갈까? (5월, 10월), 시각화(막대차트)
1-2. 통계란?
- 이해를 기반으로 다음을 예측하는 자연스러운 일
- 집단을 이해하고 예측한다.
- 관찰 -> 이해 -> 예측 -> 결정
1-3. 기술통계와 추론통계
- 기술통계
: 수집된 데이터의 요약과 설명
(ex: 평균, 표준편차, 중앙값, 사분위수, 최빈값 - 추론 통계
: 기술 통계 결과를 기반으로 일반화, 예측, 추정
(ex: 가설검증)
2. 기술통계 요소
2-1. 평균
- 집단을 잘 표현하는 대푯값(숫자).
- 대푯값으로 집단을 비교할 수 있다.
- 최초의 예측 모델
2-2. 표준편차
- 집단의 개별 값이 궁금하다.
- 집단의 분포 정도를 볼 수 있다.
- 분포를 통해, 개별 값이 나타날 확률을 알 수 있다.
2-3. 분산
- 두 집단의 분포 정도를 비교
2-4. 왜도와 첨도
- 왜도
: 중앙값이 평균(정규분포 중심)보다 왼쪽(양수) or 오른쪽(음수)에 있다. - 첨도
: 몰려있는 정도 - 양의 첨도: 평균에 몰려있다.
- 음의 첨도: 평균으로 부터 퍼져있다.
2-5. 중앙값
- 이상치 때문에 평균의 대표성이 무너질 때, 중앙값을 사용한다.
- 이상치는 거의 활용하지 않는다.
(ex: 예외적으로 이상치가 위험요소가 되어, 감시하는 경우)
2-6. 사분위수
- 이상치를 보완한다.
- 분포를 조금 더 알고 싶은 경우
- Box plot
: 가장 작은 수, 1/4, 중앙값, 3/4, 가장 높은 수
.png)
a) 채식주의자와 비 채식주의자 키 분포를 비교
상대적으로 채식주의자는 분산이 더 적다. 채식주의자는 양의 첨도. 비채식주의자는 음의 첨도. 채식주의자는 왜도가 오른쪽에 비채식주의자는 왜도가 왼쪽에 있다. (최소값, 최대값, 평균)
b) 두 집단을 비교할 때, 절대빈도보다 상대빈도를 사용하는 것이 더 나은 이유
채식주의자의 숫자가 비채식주의자에 비해 압도적으로 적다. 차트를 비교할 때, 비교하기 편한 y축 선정하기 어렵기 때문에, 절대값(인원) 대신 상대값(%)이 비교하기 편하다.
c) 채식주의자가 되면 학생들의 평균 키가 작아진다고 결론을 내리는 것이 합리적일까요?
키에 영향을 주는 요인이 너무 많기 때문에, 식단만 가지고 합리화 하기 어렵다. 두 분포 모양이 달라서, 평균 키로 결론 내기 애매한 것 같습니다.
.png)
.png)
(a) 전체적으로 어망에 걸린 숫자의 총량은 늘었다. 분산은 줄었다. 귀신 및 혹등고래가 어망에 걸린 숫자는 늘었고, 밍크 및 다른 고래의 숫자는 더 줄었다.
(b) 두 고래의 어망에 걸린 숫자의 증가는 큰 차이 없지만 비율로 따졌을 때, 귀신고래는 100%, 혹등고래는 30%로 증가했기 때문이다.
(b) 두 고래의 어망에 걸린 숫자의 증가는 큰 차이 없지만 비율로 따졌을 때, 귀신고래는 100%, 혹등고래는 30%로 증가했기 때문이다.
3. RFM (사용자 그룹 또는 등급 분류)
: CRM 기법 중 하나, 사용자 별로 얼마나 '최근에', '자주', '금액' 지출했는지 사용자들의 분포를 확인3-1. 분류 기준
- R-최근에:
- 마지막 구매일 3개월 이하=3
- 3초과~6개월=2
- 6개월 초과=1
- F-자주:
- 구매횟수 100초과=3
- 50초과~100=2
- 50개이하 = 1
- M-구매금액:
- 200,000$ 초과=3
- 100,000초과~200,000이하=2
- 100,000이하=1
3-2. Fomula (함수)
- File - Data Table
- File - Fomula - Data Table
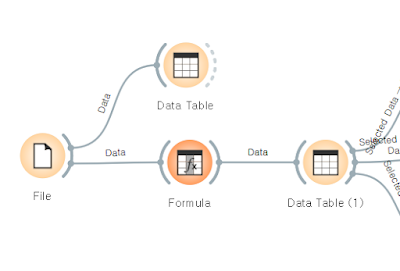
조건문을 사용하여, 값 입력. (값 if 조건문)
이때 조건문은 숫자만 인식하므로 산술 조건만 가능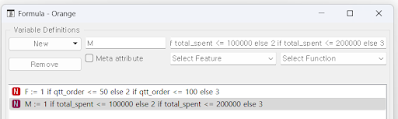
- Data Table - Select Rows - Formula - Concatenate
( 숫자 데이터가 아닌 경우, 이 방법을 사용)



범위 값의 row를 선택


합치기

Data Table (합친 뒤에 Data Table로 데이터 확인)
- Data Table - Select Rows - Data Table - Concatenate
( 조건에 따라 row를 나누고, 나눈 조건으로 데이터 정렬을 한다. )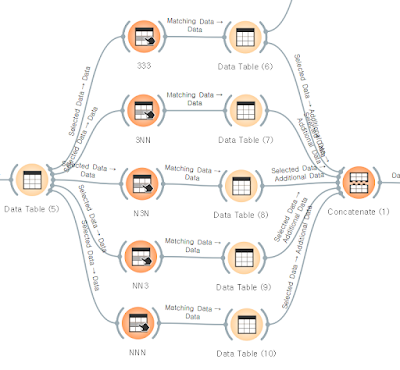
Select rows 조건 입력
합치기 (고객 등급별 나열)


4. 클러스터링 (군집화)
- 데이터를 주면 알아서 군집
- 마케팅 전략 활용
: 고객의 통계학적 정보(성별, 나이, 지역, 수입)에 맞게 고객군 설정

- k - Means
군집을 입력한다.(Fixed) 군집 수를 추천 받을 수 있다.

5. 장바구니 연관분석 - Association
- 고객 연관 규칙 분석
- 고객 패턴을 분석해서 매출 상승
( ex: 매대 제품 진열 및 IT서비스 컨텐츠 배치 등에 활용 )
- Frequent Itemsets
( Minimal support는 1%로 조정. 출현 빈도 조정. )
- 특정 item을 선택한 뒤, 그 다음 item을 선정할 확률을 나타낸다.
- Association Rules
- 어떤 item 집단을 선택했을 때, 반드시 선택하는 item이 무엇인지 나타낸다.



Tags:
서비스기획_Tool
